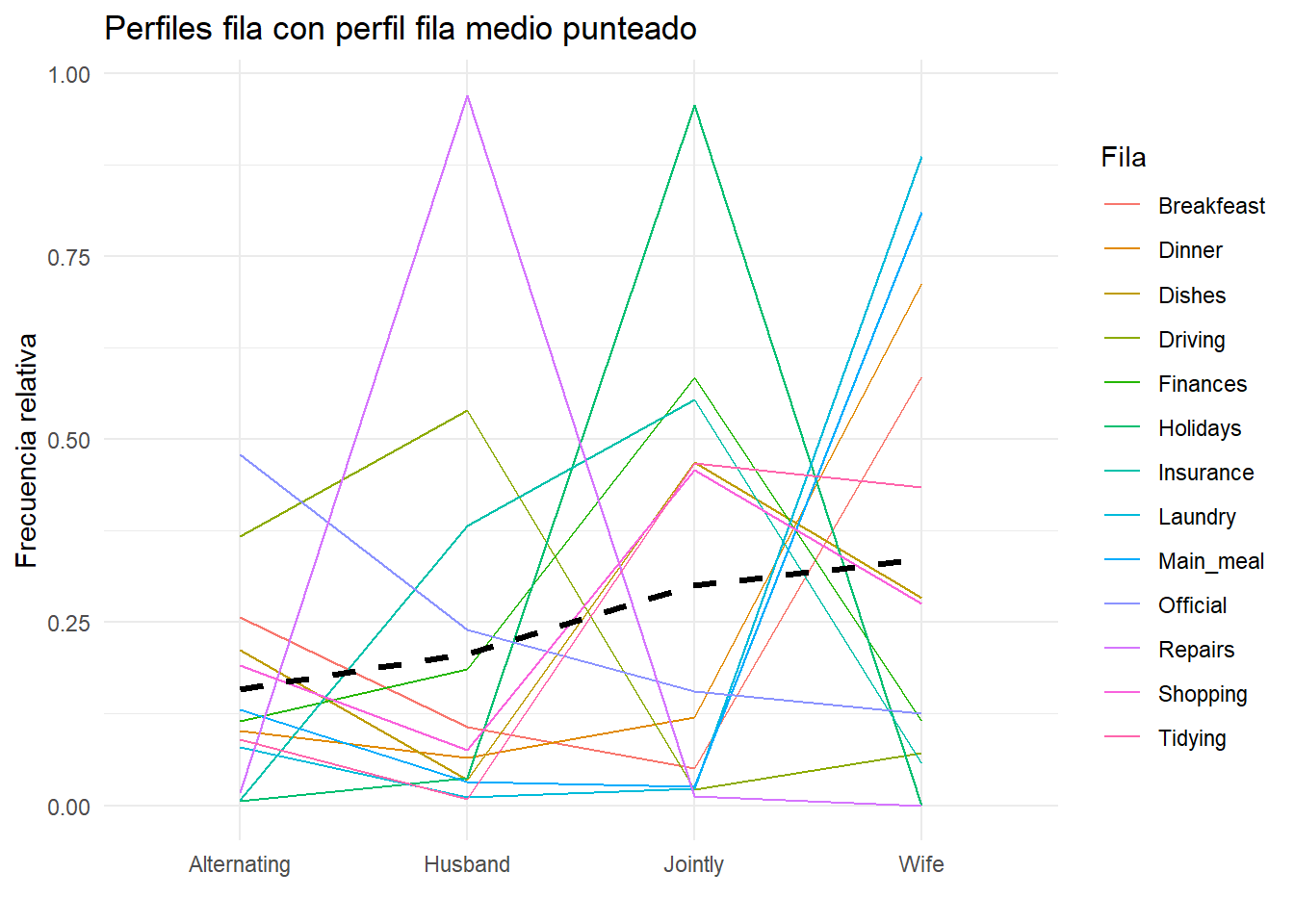
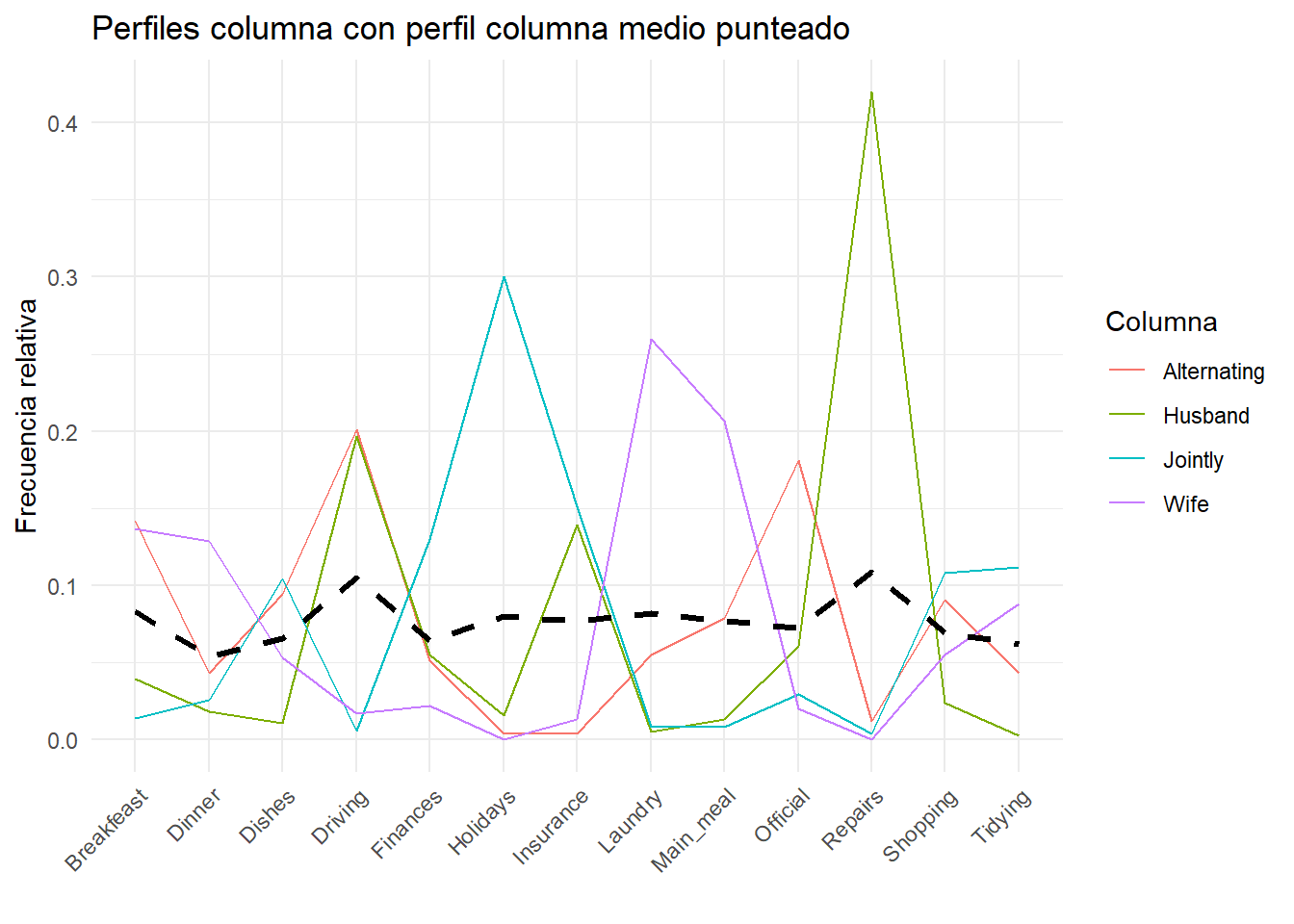
dt <-as.table(as.matrix(housetasks))gplots::balloonplot(t(dt), main ="Tareas del hogar", xlab ="", ylab="",label =FALSE, show.margins =FALSE)
Análisis de Correspondencia Simple
Test de Independencia
Supuestos
El tamaño de muestra n debe ser mayor a 50
Las observaciones deben ser independientes
Las frecuencias esperadas deben ser mayores a 5. Se admite como máximo un 20% de casillas con frecuencias esperadas menores a 5. Si no se cumple, puede solucionarse aumentando el tamaño de la muestra o agrupando categorías.
Ho Las tareas de hogar y quien las realiza son independientes.
El AC es similar a PCA, pero para variables categóricas
Es una técnica descriptiva que busca representar gráficamente datos categóricos a fin de identificar correspondencia o asociación entre las categorías de filas y columnas.
El objetivo es reducir la dimensionalidad (en general 2 ejes principales): se pretende proyectar los puntos fila en un espacio de dimensión menor de manera que las filas que tengan la misma estructura estén próximas y las que tengan una estructura muy diferente, alejadas (ídem columnas)
En lugar de trabajar con la matriz varianzas/covarianzas o correlaciones como en PCA, se utiliza la matriz de distancias chi-cuadrado
Se extraen los ejes principales de manera de maximizar la asociación entre filas y columnas (máxima inercia)
Estos ejes son combinaciones lineales de las variables originales y son independientes entre sí
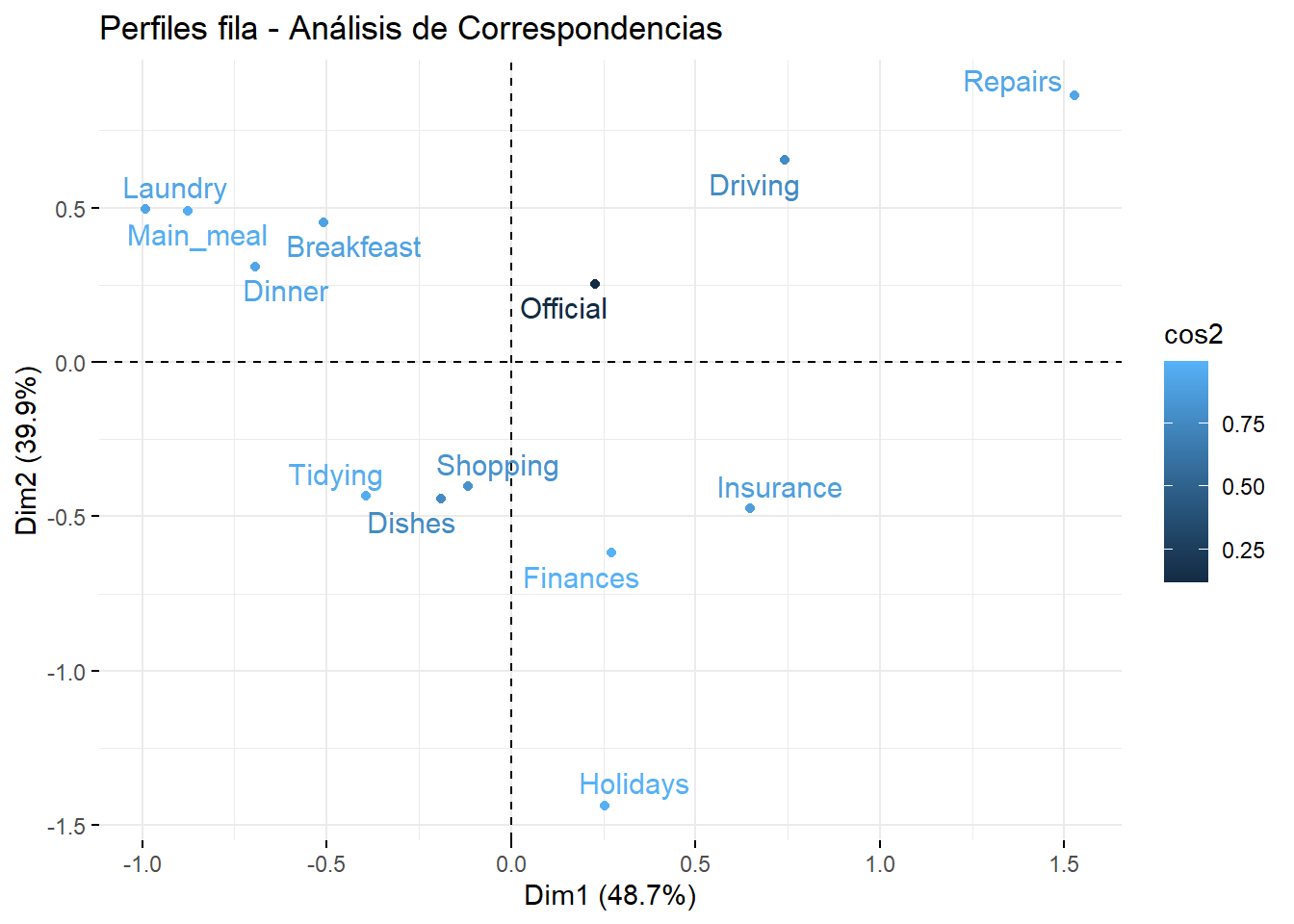
¿Están relacionadas Las tareas del hogar con quien realiza la tarea en la pareja?
Código
house.ca <-CA(housetasks, graph =FALSE)
Código
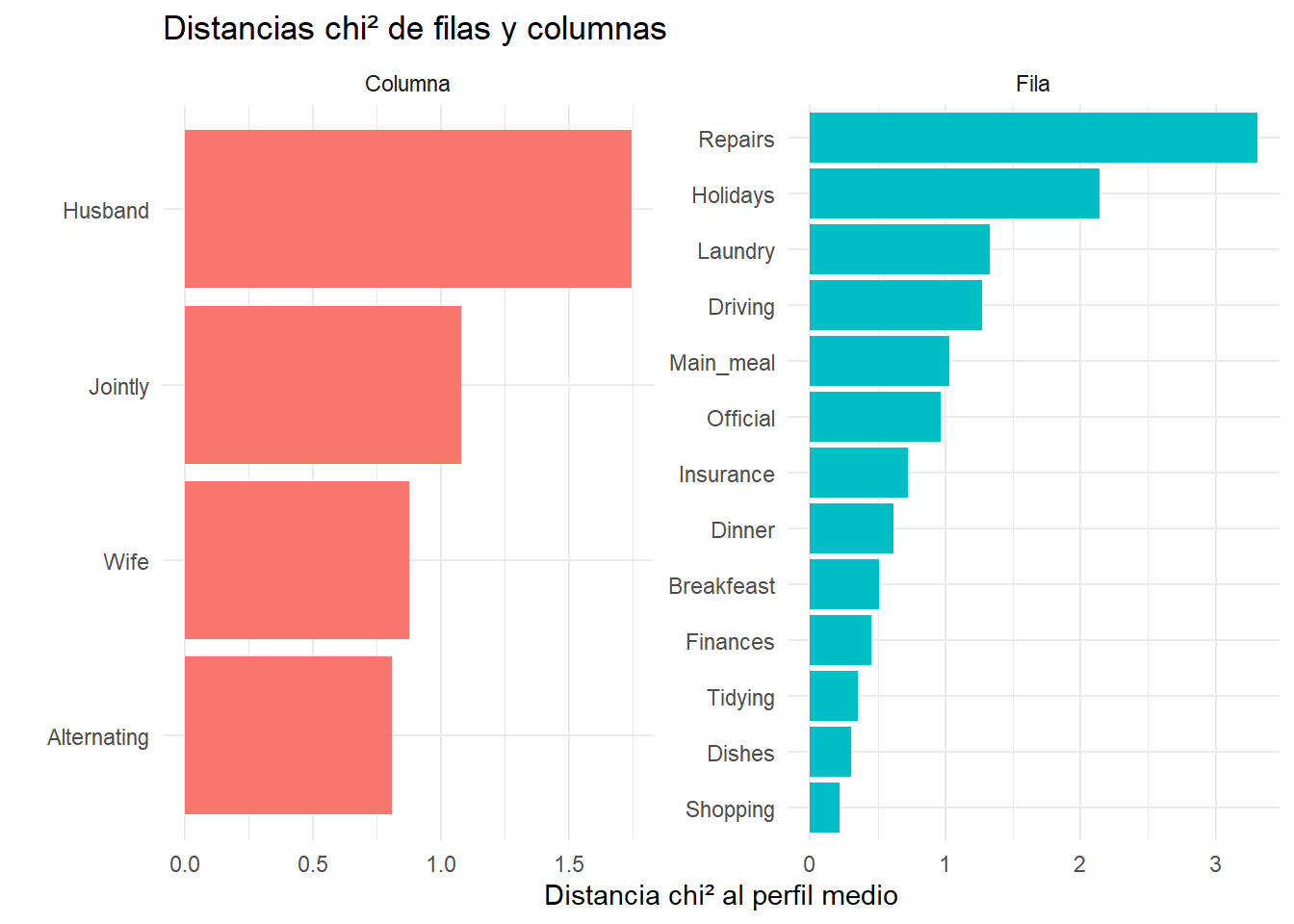
# Distancia chi² de filas al perfil mediodist_filas <-rowSums(house.ca$row$coord^2)# Distancia chi² de columnas al perfil mediodist_columnas <-rowSums(house.ca$col$coord^2)# a data framedf_dist_filas <-data.frame(Categoria =rownames(housetasks),Distancia_Chi2 = dist_filas,Tipo ="Fila")df_dist_columnas <-data.frame(Categoria =colnames(housetasks),Distancia_Chi2 = dist_columnas,Tipo ="Columna")df_dists <-bind_rows(df_dist_filas, df_dist_columnas)# Gráficoggplot(df_dists, aes(x =reorder(Categoria, Distancia_Chi2), y = Distancia_Chi2, fill = Tipo)) +geom_col(show.legend =FALSE) +facet_wrap(~Tipo, scales ="free") +coord_flip() +labs(title ="Distancias chi² de filas y columnas",x ="", y ="Distancia chi² al perfil medio") +theme_minimal()
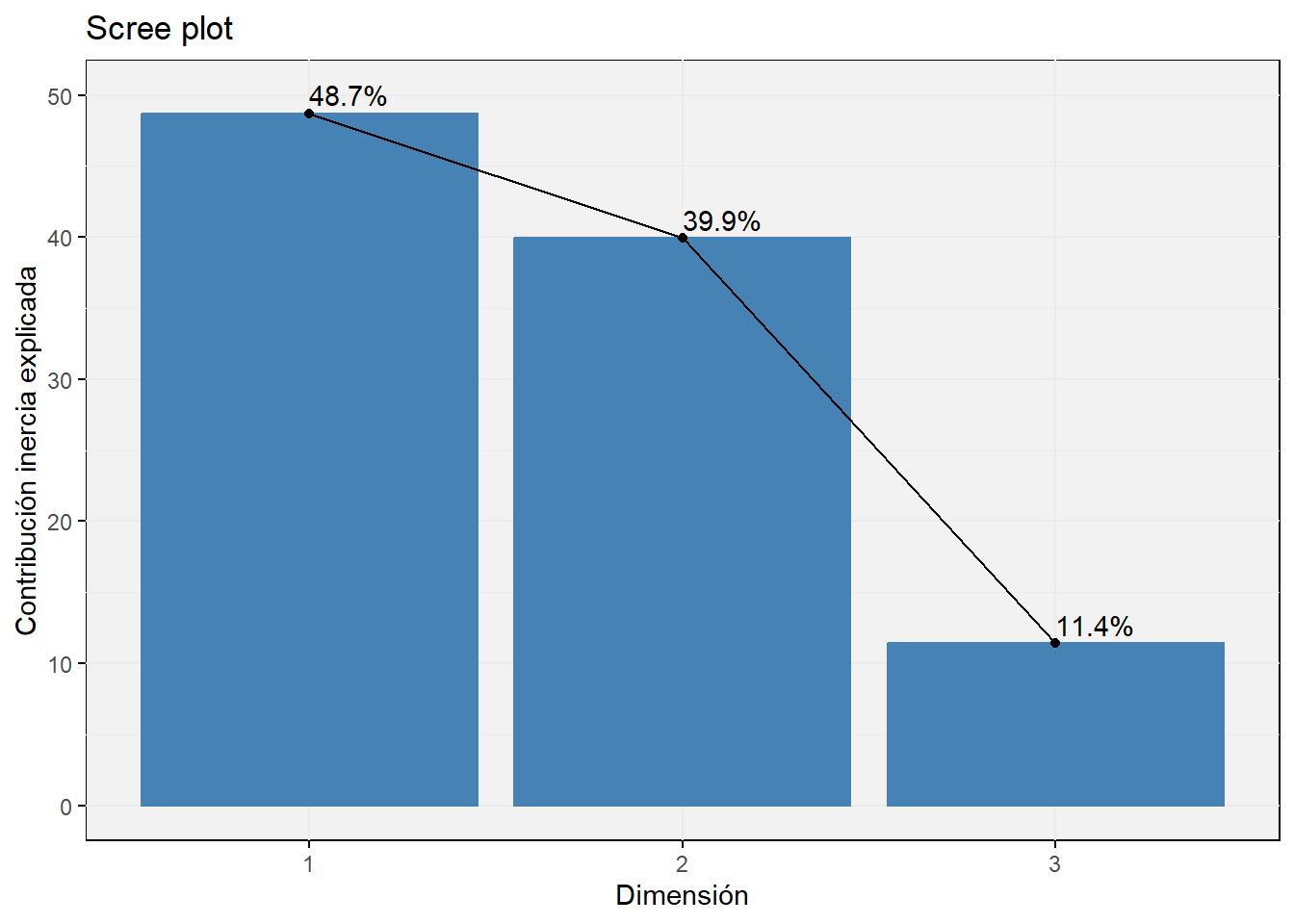
Inercia
Es una medida de la falta de independencia, resume la información total contenida en la tabla de doble entrada.
Está directamente relacionada con el estadístico \(\chi^{2}\): \(I =\frac{\chi^{2}}{n}\)
Cuanto mayor sea la diferencia entre las frecuencias observadas y las esperadas, y por lo tanto mayor dependencia entre filas y columnas, mayor inercia, mayor \(\chi^{2}\)
Equivale a la varianza total en ACP
Código
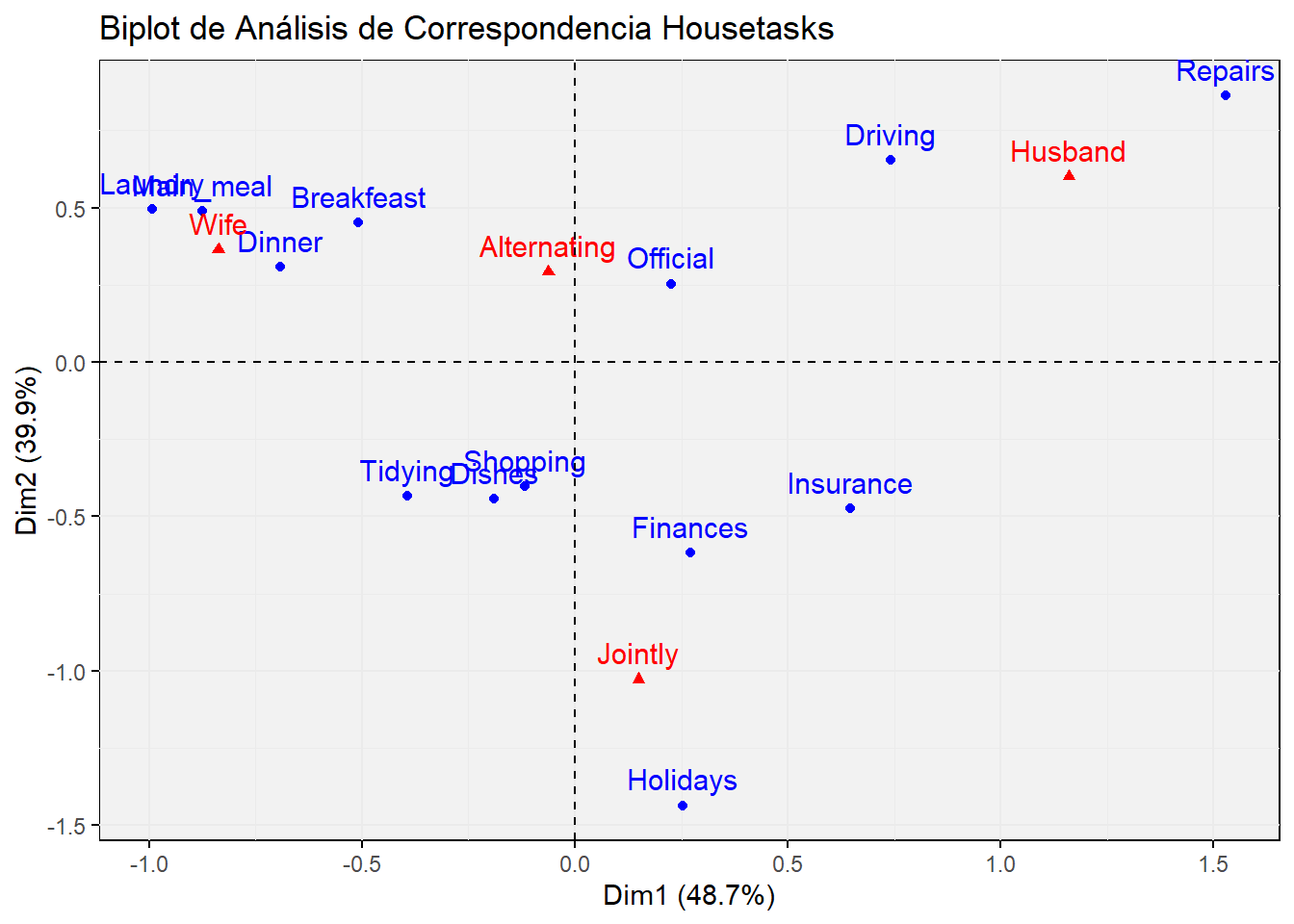
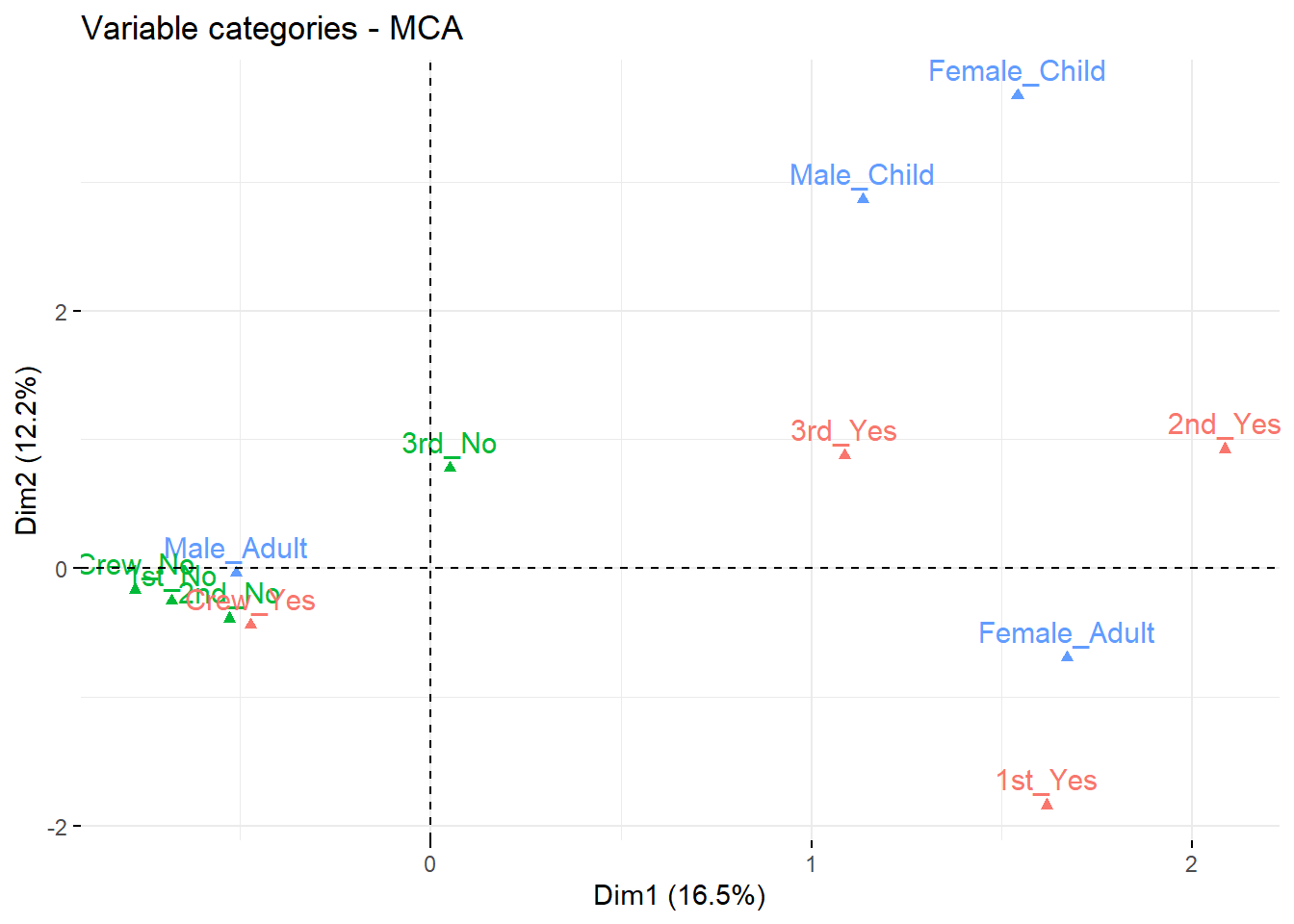
# Análisis de correspondencias de filas y columnas en simultáneofviz_ca_biplot(house.ca) +theme(axis.text.x =element_text(angle=0)) +labs(title ='Biplot de Análisis de Correspondencia Housetasks')+theme(panel.background =element_rect(fill ="grey95"))
Cuanto mayor la distancia al origen, mayor es la contribución a la falta de independencia
Código
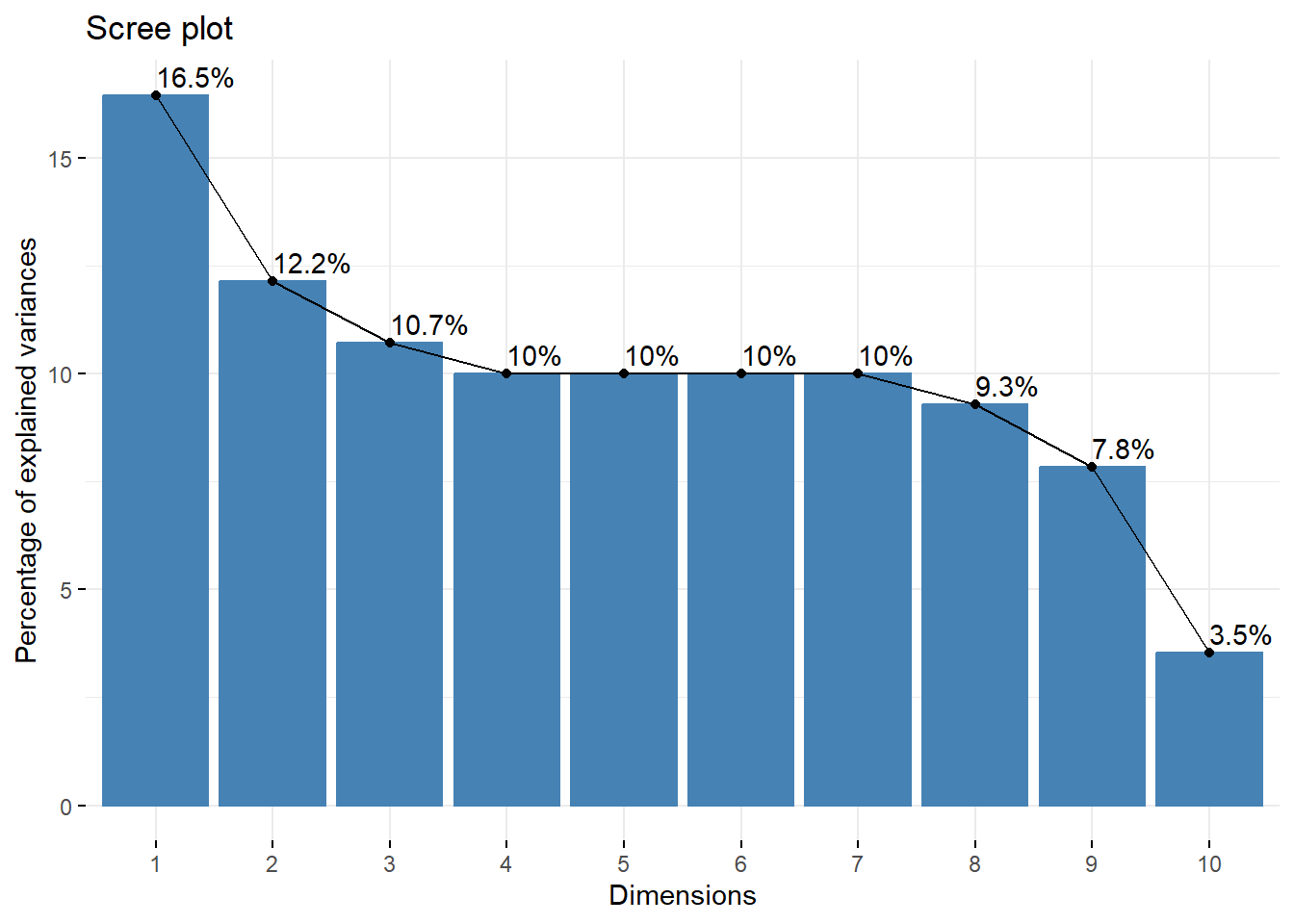
fviz_screeplot(house.ca, addlabels =TRUE, ylim =c(0, 50))+theme(axis.text.x =element_text(angle=0)) +labs(title ='Scree plot', x ='Dimensión', y ='Contribución inercia explicada')+theme(panel.background =element_rect(fill ="grey95"))
Código
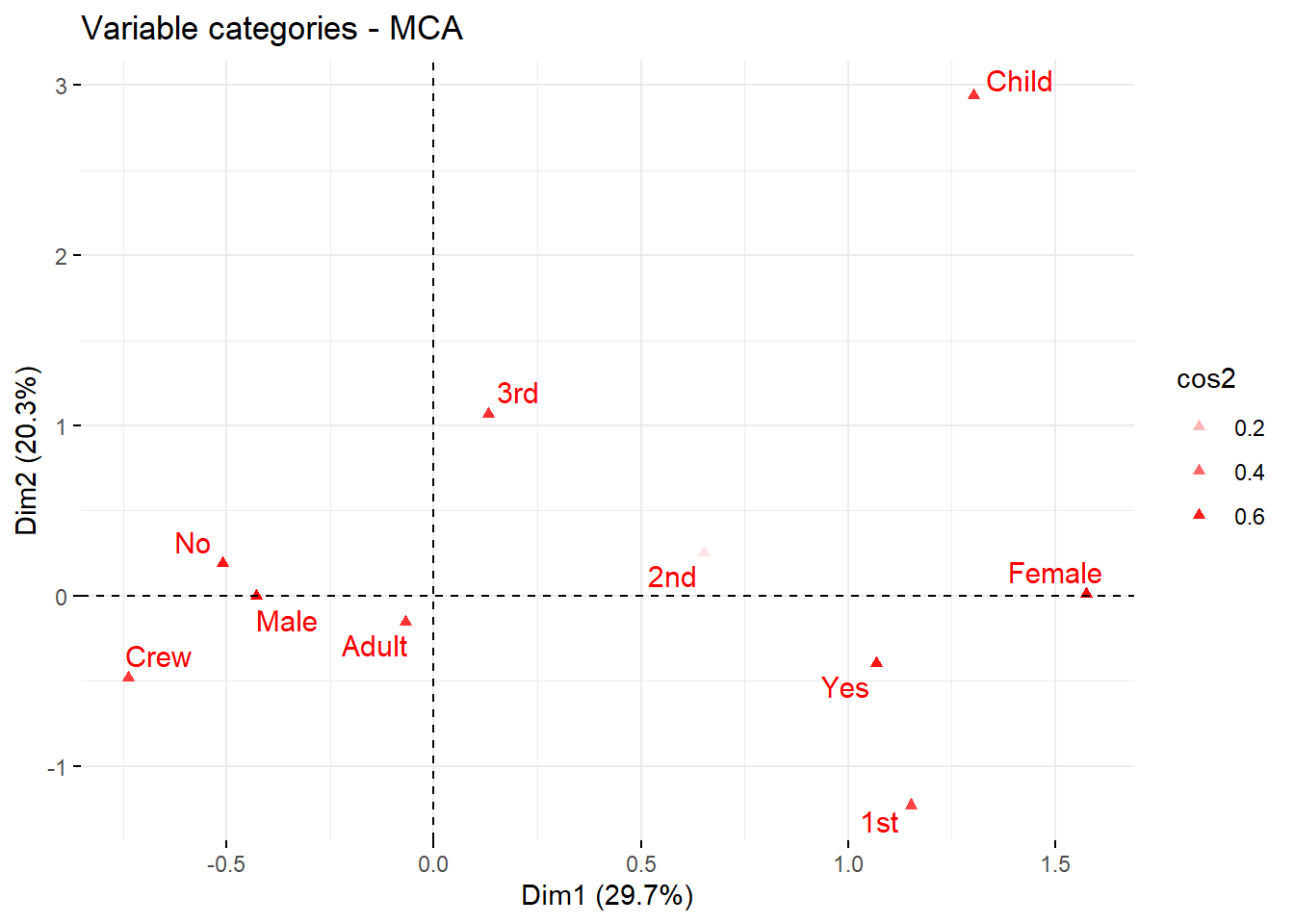
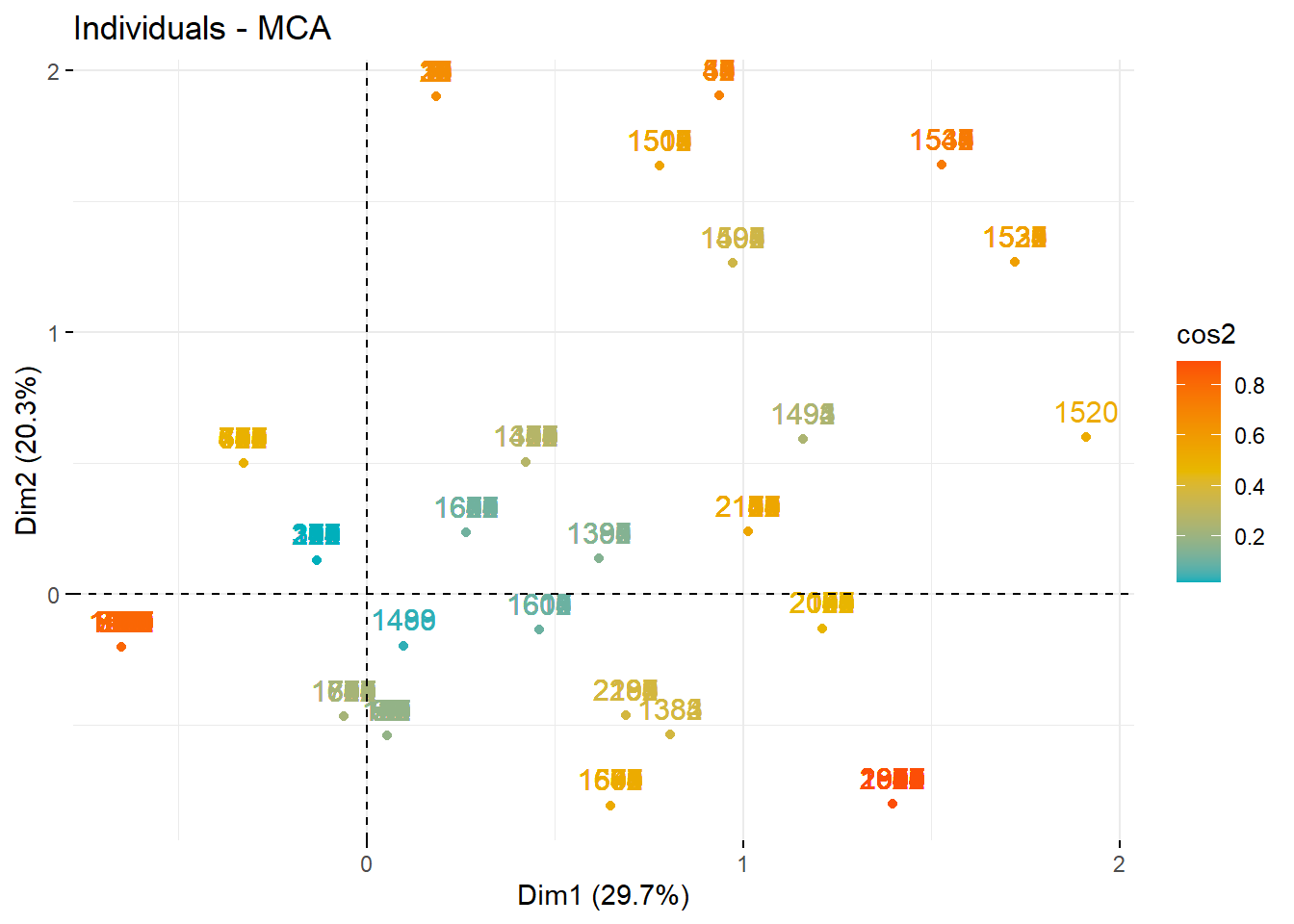
fviz_ca_row(house.ca, repel =TRUE, col.row ="cos2", # color de puntoslabel ="all", title ="Perfiles fila - Análisis de Correspondencias")
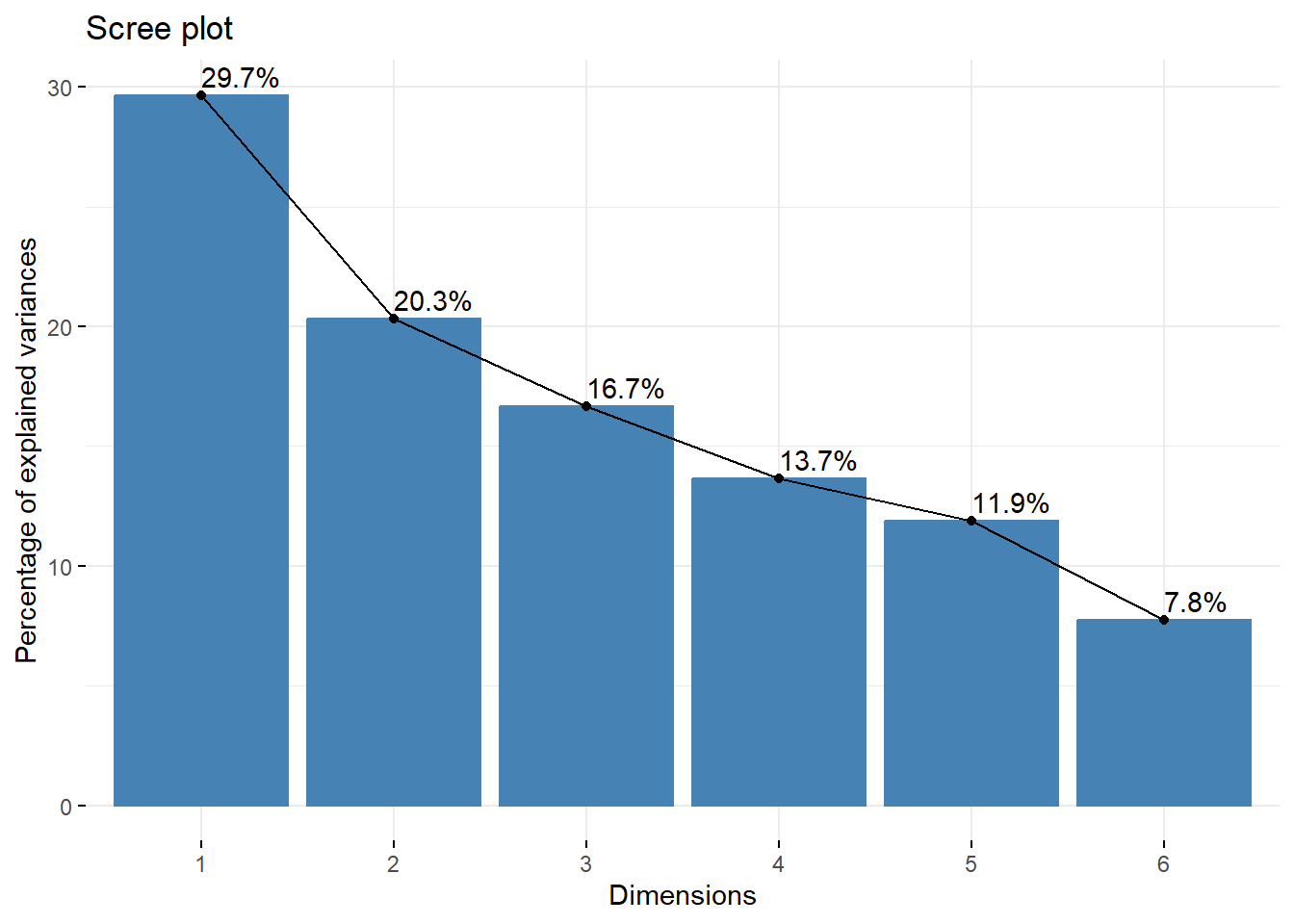
Análisis de Correspondencia Múltiple
Código
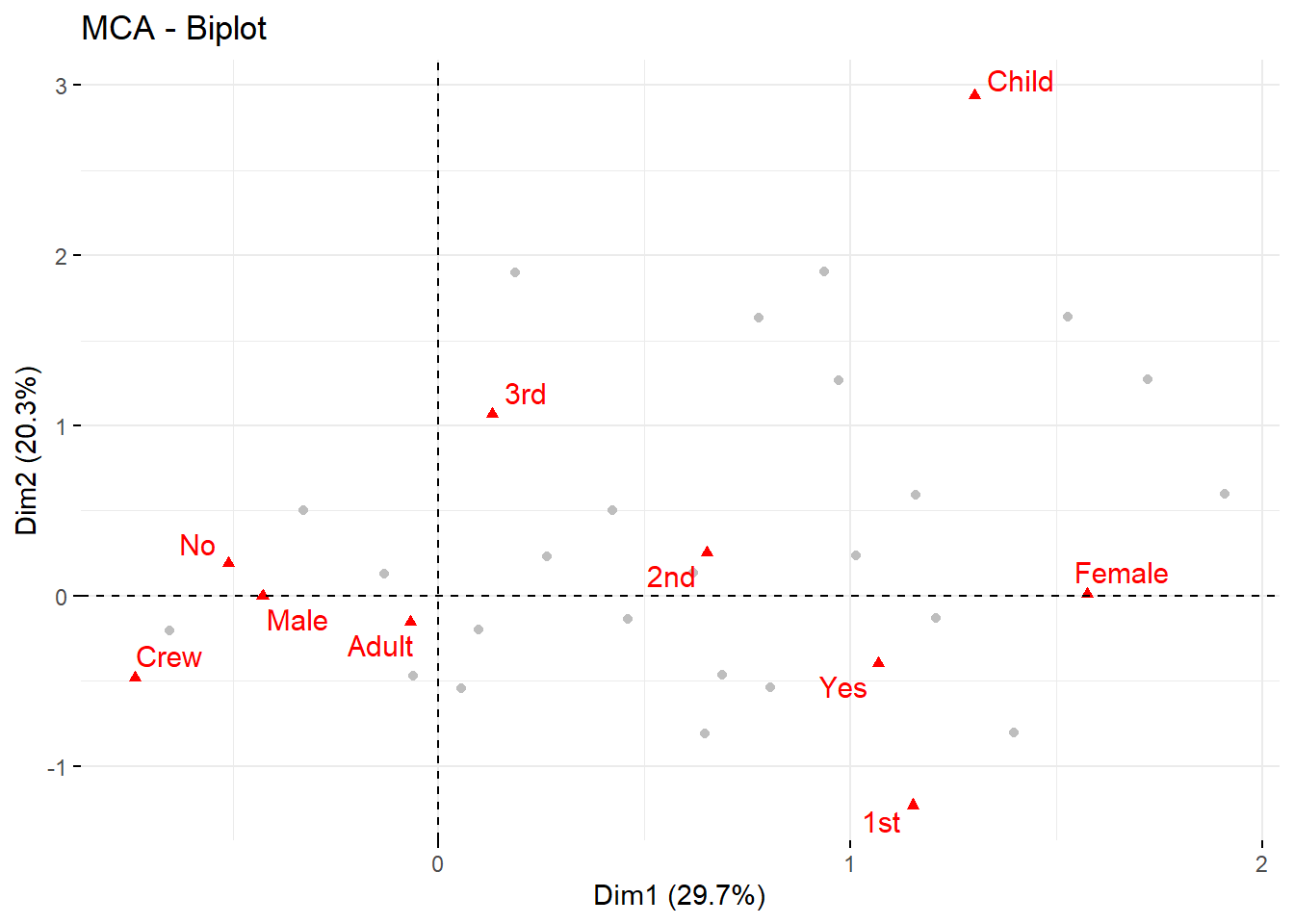
data("Titanic")# Paso a data frametitanic <-as.data.frame(Titanic)# Expando la tabla de frecuenciastitanic <- titanic[rep(1:nrow(titanic), titanic[,5]),-5]# Reseteo nombre de filasrownames(titanic) <-NULLhead(titanic)
Class Sex Age Survived
1 3rd Male Child No
2 3rd Male Child No
3 3rd Male Child No
4 3rd Male Child No
5 3rd Male Child No
6 3rd Male Child No
Código
# Armo matriz de Burtlibrary(anacor)burt <-burtTable(titanic)burt
#Grafico matriz de Burtburt2 <-as.table(as.matrix(burt))gplots::balloonplot((burt2), main='Matriz de Burt de datos Titanic', label=F, show.margins = F,dotcolor="pink", text.size=0.7,colsrt=45,colmar=2.5)
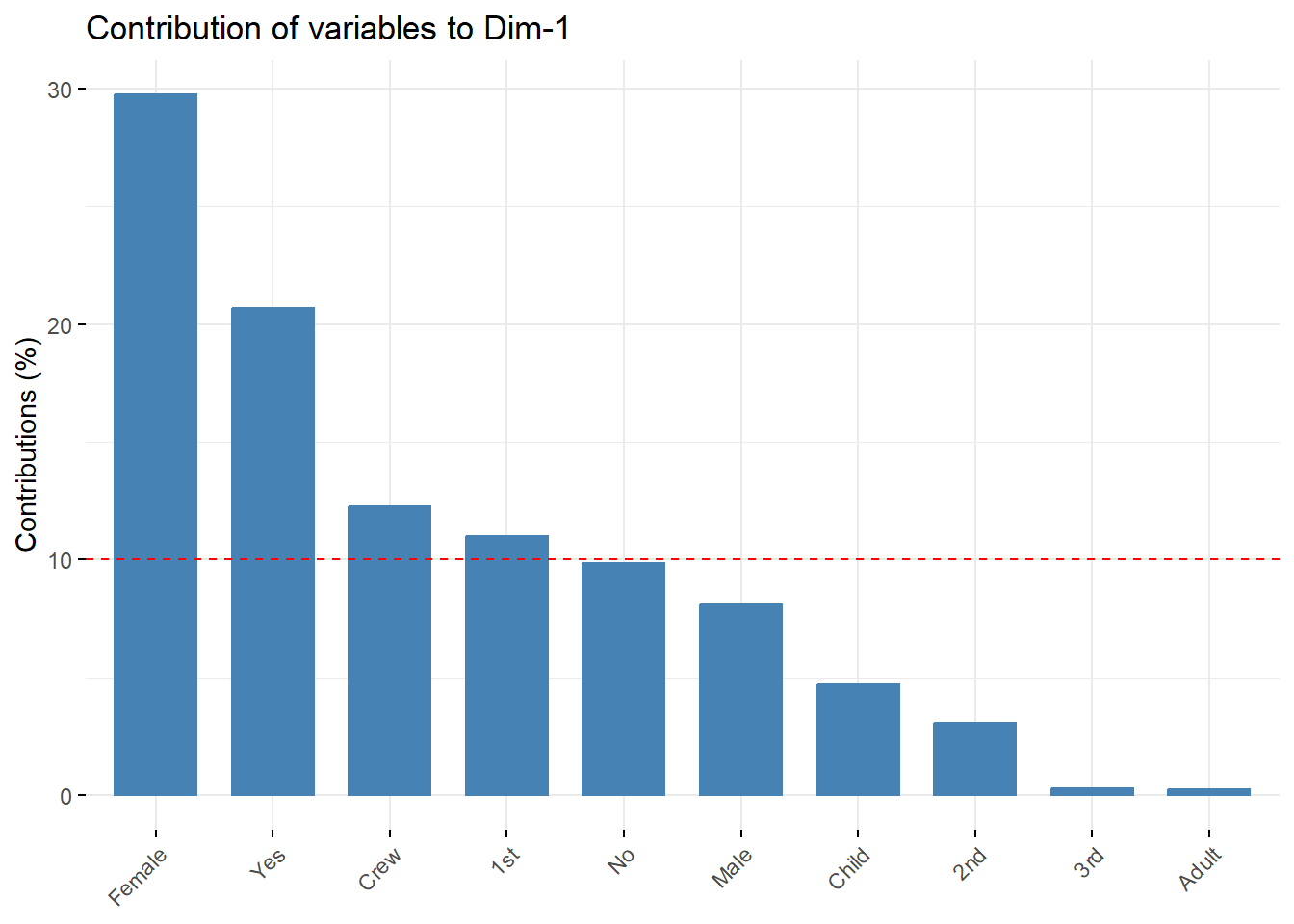
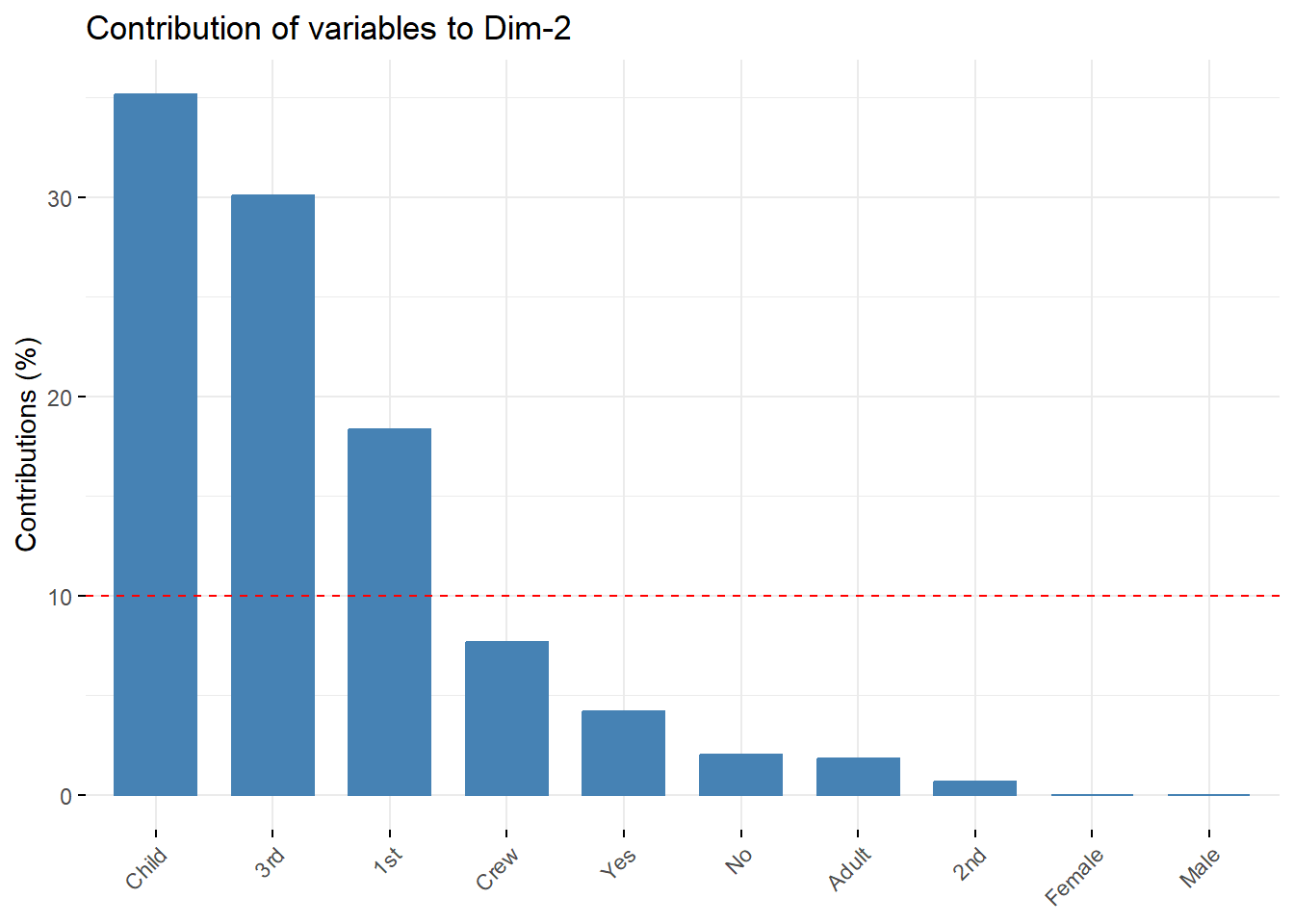
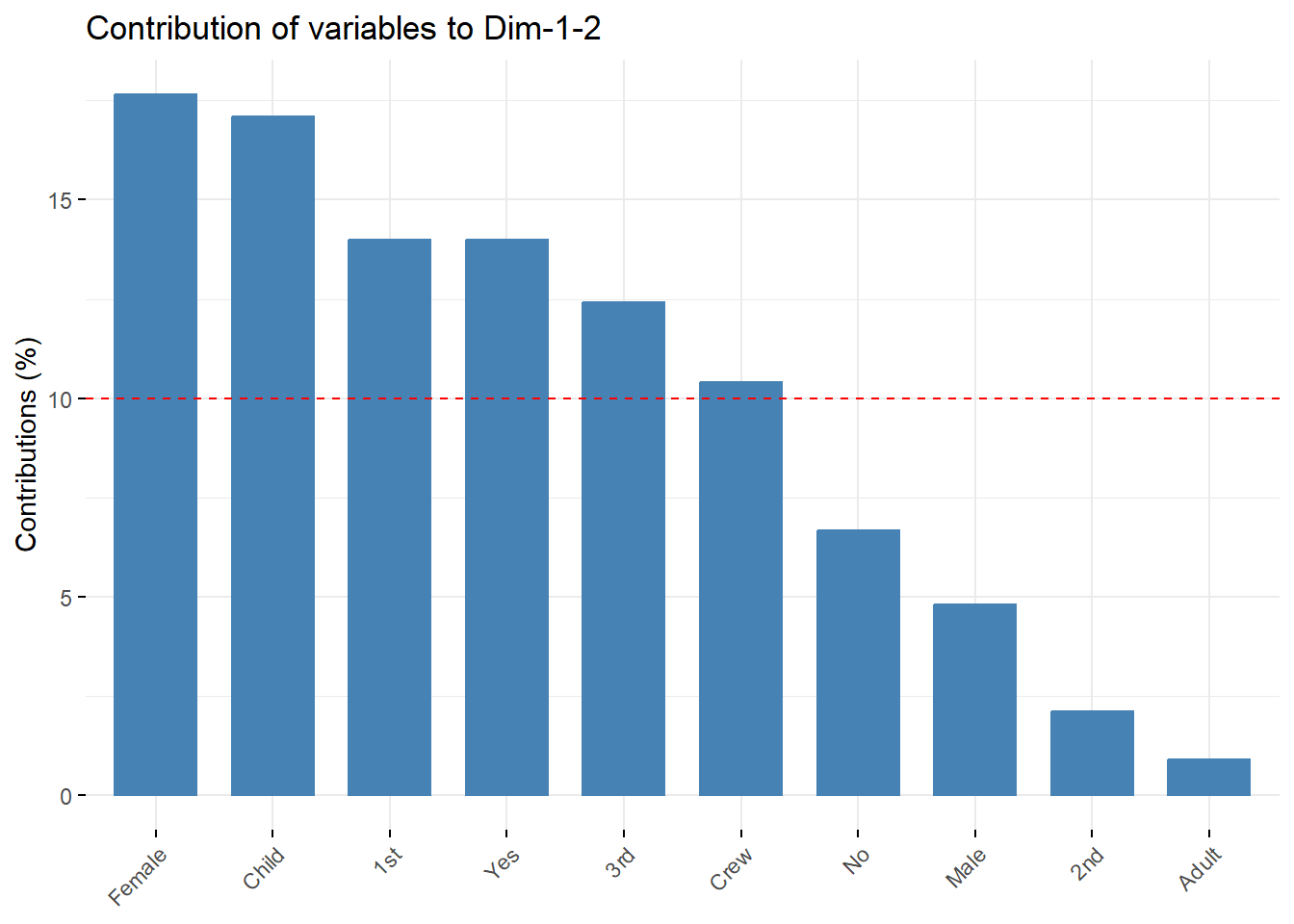
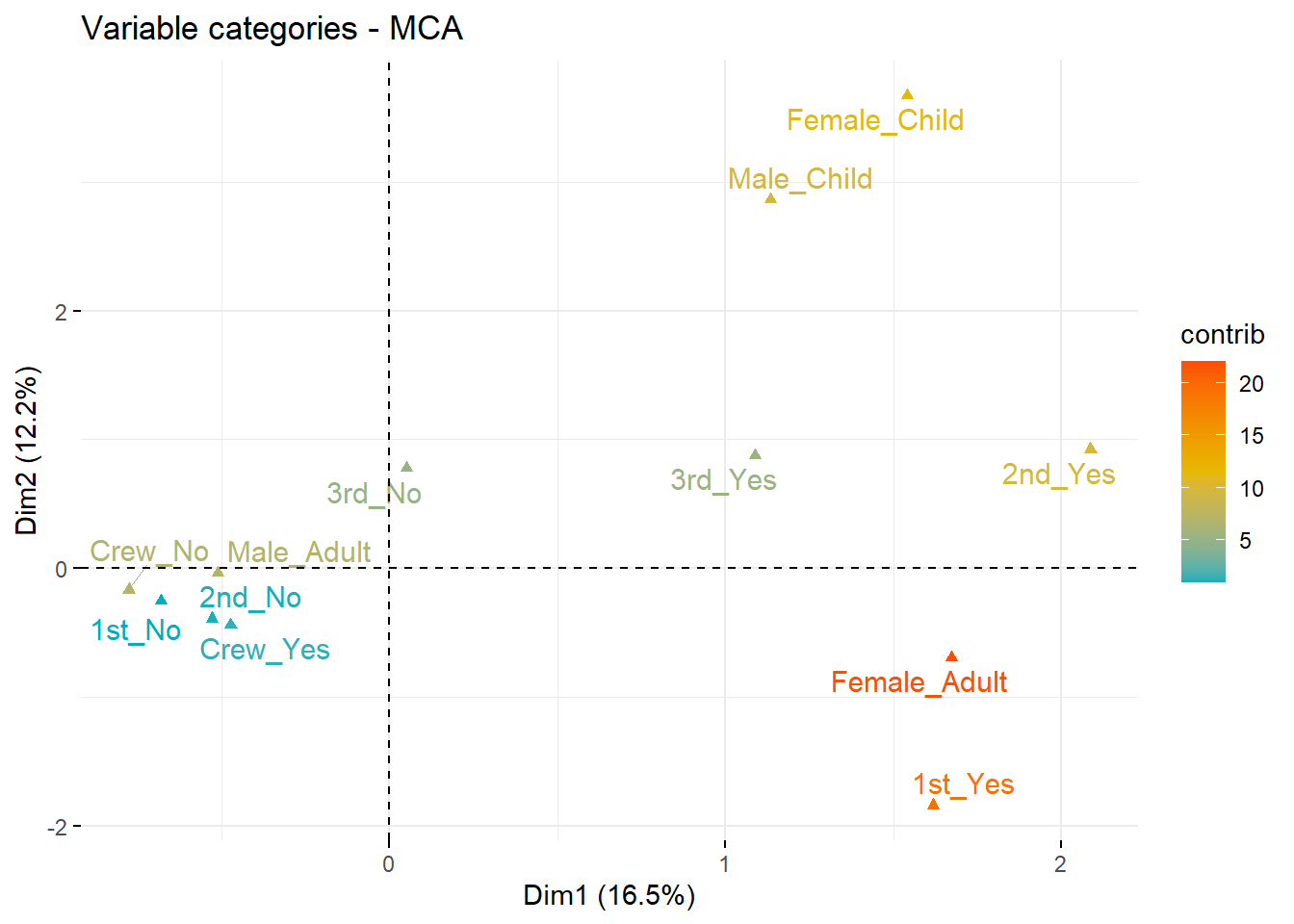
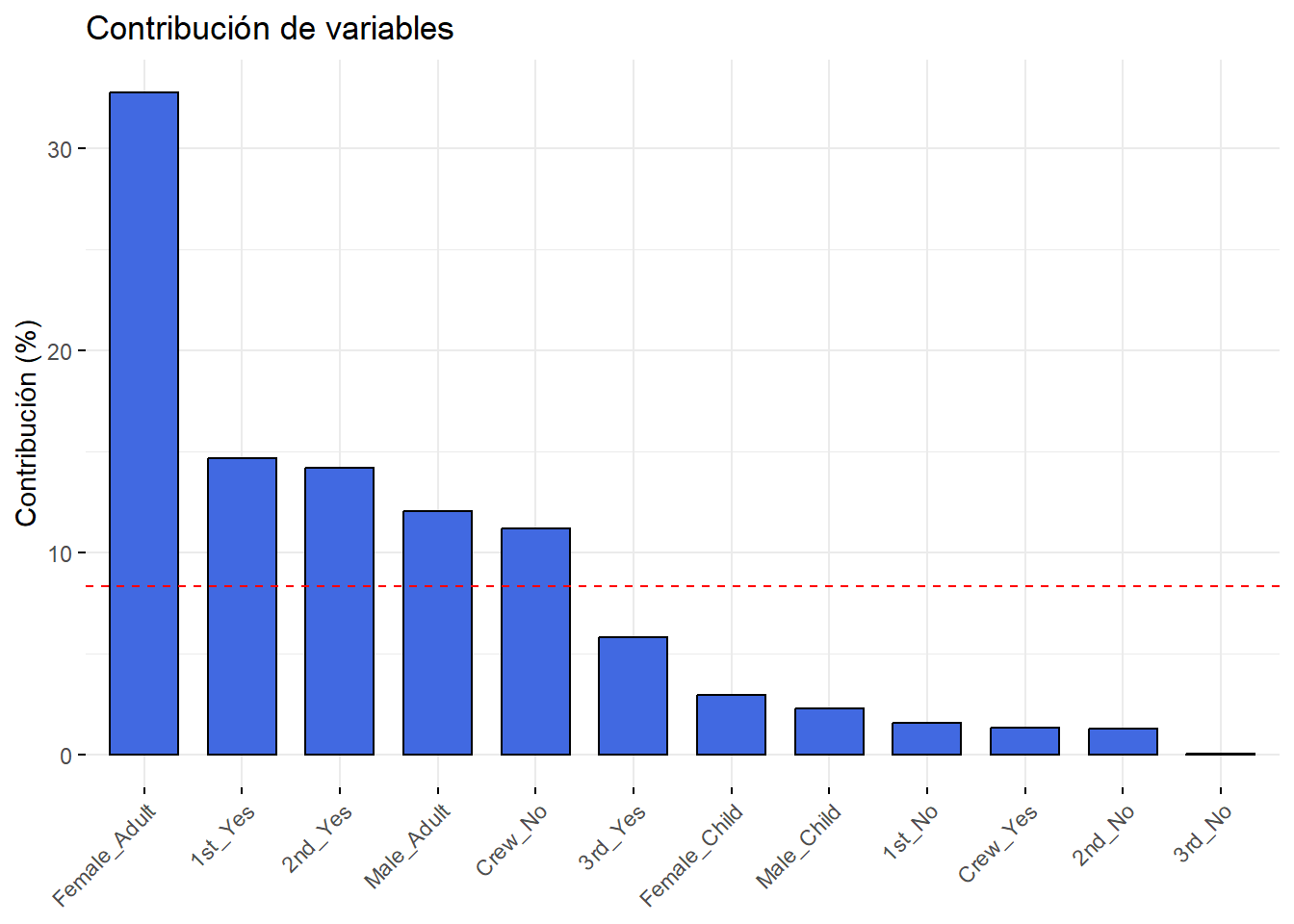
# Análisis de contribución de variables a dimensión 1fviz_contrib(Tit2.mca,choice="var",axes=1, fill="royalblue",color ="black")+theme(axis.text.x =element_text(angle=45)) +labs(title ='Contribución de variables', x ='Variables', y ='Contribución (%)')
Ejecutar el código
---title: "Análisis de Correspondencia Simple y Múltiple"author: "Pamela E. Pairo"lang: esformat: html: theme: flatly code-fold: show code-tools: true toc: true toc-location: left---```{r setup, include=FALSE}knitr::opts_chunk$set(echo = TRUE)knitr::opts_chunk$set(message = FALSE)knitr::opts_chunk$set(warning = FALSE)library(tidyverse)library(factoextra)library(FactoMineR)library(gmodels)library(vcdExtra)``````{r}data(housetasks)housetasks``````{r}dt <-as.table(as.matrix(housetasks))gplots::balloonplot(t(dt), main ="Tareas del hogar", xlab ="", ylab="",label =FALSE, show.margins =FALSE)```# Análisis de Correspondencia Simple## Test de Independencia**Supuestos**- El tamaño de muestra n debe ser mayor a 50- Las observaciones deben ser independientes- Las frecuencias esperadas deben ser mayores a 5. Se admite como máximo un 20% de casillas con frecuencias esperadas menores a 5. Si no se cumple, puede solucionarse aumentando el tamaño de la muestra o agrupando categorías.Ho Las tareas de hogar y quien las realiza son independientes.```{r}chisq.test(housetasks)```## Análisis de perfiles### Perfil Fila```{r}CrossTable(as.matrix(housetasks),prop.t=FALSE,prop.r=TRUE, #proporciones filasprop.c=FALSE, prop.chisq=FALSE)```Si hay independencia, los perfiles fila serán homogéneos y similares al perfil medio```{r}# Calcular perfiles filaperfil_fila <-prop.table(as.matrix(housetasks), margin =1)# Convertir a data frame largodf <-as.data.frame(perfil_fila)df$fila <-rownames(perfil_fila)df_long <-pivot_longer(df, -fila, names_to ="columna", values_to ="proporcion")# Calcular perfil fila medioperfil_fila_medio <-colMeans(perfil_fila)perfil_fila_medio_df <-data.frame(fila ="Promedio filas",columna =names(perfil_fila_medio),proporcion =as.numeric(perfil_fila_medio))# Unir ambosdf_plot <-bind_rows(df_long, perfil_fila_medio_df)# Graficarggplot(df_plot, aes(x = columna, y = proporcion, group = fila)) +# Líneas normales con color automáticogeom_line(data =subset(df_plot, fila !="Promedio filas"),aes(color = fila),linewidth =0.5) +# Línea negra y punteada para el promediogeom_line(data =subset(df_plot, fila =="Promedio filas"),color ="black", linetype ="dashed", linewidth =1.2) +labs(title ="Perfiles fila con perfil fila medio punteado",x =" ",y ="Frecuencia relativa",color ="Fila") +theme_minimal()```### Perfil Columna```{r}CrossTable(as.matrix(housetasks),prop.t=FALSE,prop.r=FALSE, #proporciones filasprop.c=TRUE, prop.chisq=FALSE)``````{r}# Calcular perfiles columnaperfil_columna <-prop.table(as.matrix(housetasks), margin =2)# Convertir a data frame largo, primero transponerdf_col <-as.data.frame(perfil_columna)df_col$fila <-rownames(df_col)df_col_long <-pivot_longer(df_col, -fila, names_to ="columna", values_to ="proporcion")# Calcular perfil columna medio (promedio por fila)perfil_columna_medio <-rowMeans(perfil_columna)perfil_columna_medio_df <-data.frame(columna ="Promedio columnas",fila =names(perfil_columna_medio),proporcion =as.numeric(perfil_columna_medio))# Unir ambosdf_plot_col <-bind_rows(df_col_long, perfil_columna_medio_df)ggplot(df_plot_col, aes(x = fila, y = proporcion, group = columna)) +geom_line(data =subset(df_plot_col, columna !="Promedio columnas"),aes(color = columna),linewidth =0.5) +geom_line(data =subset(df_plot_col, columna =="Promedio columnas"),color ="black", linetype ="dashed", linewidth =1.2) +labs(title ="Perfiles columna con perfil columna medio punteado",x =" ",y ="Frecuencia relativa",color ="Columna") +theme_minimal()+theme(axis.text.x =element_text(angle =45, hjust =1))```## Biplot- El AC es similar a PCA, pero para **variables categóricas**- Es una técnica descriptiva que busca representar gráficamente datos categóricos a fin de identificar correspondencia o asociación entre las categorías de filas y columnas. - El **objetivo es reducir la dimensionalidad** (en general 2 ejes principales): se pretende proyectar los puntos fila en un espacio de dimensión menor de manera que las filas que tengan la misma estructura estén próximas y las que tengan una estructura muy diferente, alejadas (ídem columnas)- En lugar de trabajar con la matriz varianzas/covarianzas o correlaciones como en PCA, se utiliza la matriz de distancias chi-cuadrado- Se extraen los ejes principales de manera de maximizar la asociación entre filas y columnas (máxima inercia)- Estos ejes son combinaciones lineales de las variables originales y son independientes entre sí¿Están relacionadas Las tareas del hogar con quien realiza la tarea en la pareja?```{r}house.ca <-CA(housetasks, graph =FALSE)``````{r}# Distancia chi² de filas al perfil mediodist_filas <-rowSums(house.ca$row$coord^2)# Distancia chi² de columnas al perfil mediodist_columnas <-rowSums(house.ca$col$coord^2)# a data framedf_dist_filas <-data.frame(Categoria =rownames(housetasks),Distancia_Chi2 = dist_filas,Tipo ="Fila")df_dist_columnas <-data.frame(Categoria =colnames(housetasks),Distancia_Chi2 = dist_columnas,Tipo ="Columna")df_dists <-bind_rows(df_dist_filas, df_dist_columnas)# Gráficoggplot(df_dists, aes(x =reorder(Categoria, Distancia_Chi2), y = Distancia_Chi2, fill = Tipo)) +geom_col(show.legend =FALSE) +facet_wrap(~Tipo, scales ="free") +coord_flip() +labs(title ="Distancias chi² de filas y columnas",x ="", y ="Distancia chi² al perfil medio") +theme_minimal()```**Inercia**- Es una medida de la falta de independencia, resume la información totalcontenida en la tabla de doble entrada.- Está directamente relacionada con el estadístico $\chi^{2}$: $I =\frac{\chi^{2}}{n}$- Cuanto mayor sea la diferencia entre las frecuencias observadas y lasesperadas, y por lo tanto mayor dependencia entre filas y columnas, mayorinercia, mayor $\chi^{2}$- Equivale a la **varianza total** en ACP```{r}# Análisis de correspondencias de filas y columnas en simultáneofviz_ca_biplot(house.ca) +theme(axis.text.x =element_text(angle=0)) +labs(title ='Biplot de Análisis de Correspondencia Housetasks')+theme(panel.background =element_rect(fill ="grey95"))```Cuanto mayor la distancia al origen, mayor es la contribución a la falta de independencia```{r}fviz_screeplot(house.ca, addlabels =TRUE, ylim =c(0, 50))+theme(axis.text.x =element_text(angle=0)) +labs(title ='Scree plot', x ='Dimensión', y ='Contribución inercia explicada')+theme(panel.background =element_rect(fill ="grey95"))``````{r}fviz_ca_row(house.ca, repel =TRUE, col.row ="cos2", # color de puntoslabel ="all", title ="Perfiles fila - Análisis de Correspondencias")```# Análisis de Correspondencia Múltiple```{r}data("Titanic")# Paso a data frametitanic <-as.data.frame(Titanic)# Expando la tabla de frecuenciastitanic <- titanic[rep(1:nrow(titanic), titanic[,5]),-5]# Reseteo nombre de filasrownames(titanic) <-NULLhead(titanic)``````{r}# Armo matriz de Burtlibrary(anacor)burt <-burtTable(titanic)burt``````{r}#Grafico matriz de Burtburt2 <-as.table(as.matrix(burt))gplots::balloonplot((burt2), main='Matriz de Burt de datos Titanic', label=F, show.margins = F,dotcolor="pink", text.size=0.7,colsrt=45,colmar=2.5)```## MCA```{r}titanic_mca <-MCA(titanic, graph=F)summary(titanic_mca)``````{r}fviz_screeplot(titanic_mca, addlabels =TRUE)``````{r}fviz_mca_biplot(titanic_mca, label="var",repel =TRUE,col.ind='gray',invisible="quali")``````{r}# Análisis de variables según representatividadfviz_mca_var(titanic_mca,invisible="quali", repel =TRUE,alpha.var="cos2")``````{r}# Análisis de variables según contribución a dimensión 1 fviz_contrib(titanic_mca, choice ="var", axes =1)``````{r}# Análisis de variables según contribución a dimensión 2fviz_contrib(titanic_mca, choice ="var", axes =2)``````{r}# Análisis de variables según contribución a dimensiones 1 y 2 fviz_contrib(titanic_mca, choice ="var",axes =1:2)```Análisis de individuos```{r}# Análisis de individuosfviz_mca_ind(titanic_mca,invisible="quali", col.ind ="cos2", gradient.cols =c("#00AFBB", "#E7B800", "#FC4E07"),rapel=TRUE,# select.ind = list(contrib = 400) )```Re-analisis de datos Titanic```{r}# Flatten a 2-D, paso a dataframe y reseteo índice de filasTitanic_2D <-as.matrix(structable(Class+Survived~Sex+Age, Titanic))df_t2D <-as.data.frame(Titanic_2D)df_t2D$combinacion <-rownames(df_t2D)rownames(df_t2D) <-NULL# Expando dataframedf_t2D <-pivot_longer(df_t2D, cols=c(1:8),names_to='sobrevivió',values_to='valores' )df_t2D <-as.data.frame(df_t2D)df_t2D_exp <- df_t2D[rep(1:nrow(df_t2D), df_t2D[,3]),-3]rownames(df_t2D_exp) <-NULL``````{r}Tit2.mca <-MCA(df_t2D_exp, graph =FALSE)summary(Tit2.mca)```Scree plot```{r}#scree plotfviz_screeplot(Tit2.mca, addlabels =TRUE)``````{r}# Análisis de variablescolorest1 <-as.character(c(3,3,3,3,2,1,2,1,2,1,2,1))fviz_mca_var(Tit2.mca,invisible="quali", col.var=colorest1)+theme(legend.position='none')``````{r}fviz_mca_var(Tit2.mca, col.var="contrib",invisible="quali", repel=TRUE, gradient.cols =c("#00AFBB", "#E7B800", "#FC4E07"))``````{r}# Análisis de contribución de variables a dimensión 1fviz_contrib(Tit2.mca,choice="var",axes=1, fill="royalblue",color ="black")+theme(axis.text.x =element_text(angle=45)) +labs(title ='Contribución de variables', x ='Variables', y ='Contribución (%)')```