Rows: 5,682
Columns: 41
$ player <chr> "Cristian Castro Devenish", "Silaldo Taffarel", "Thomas…
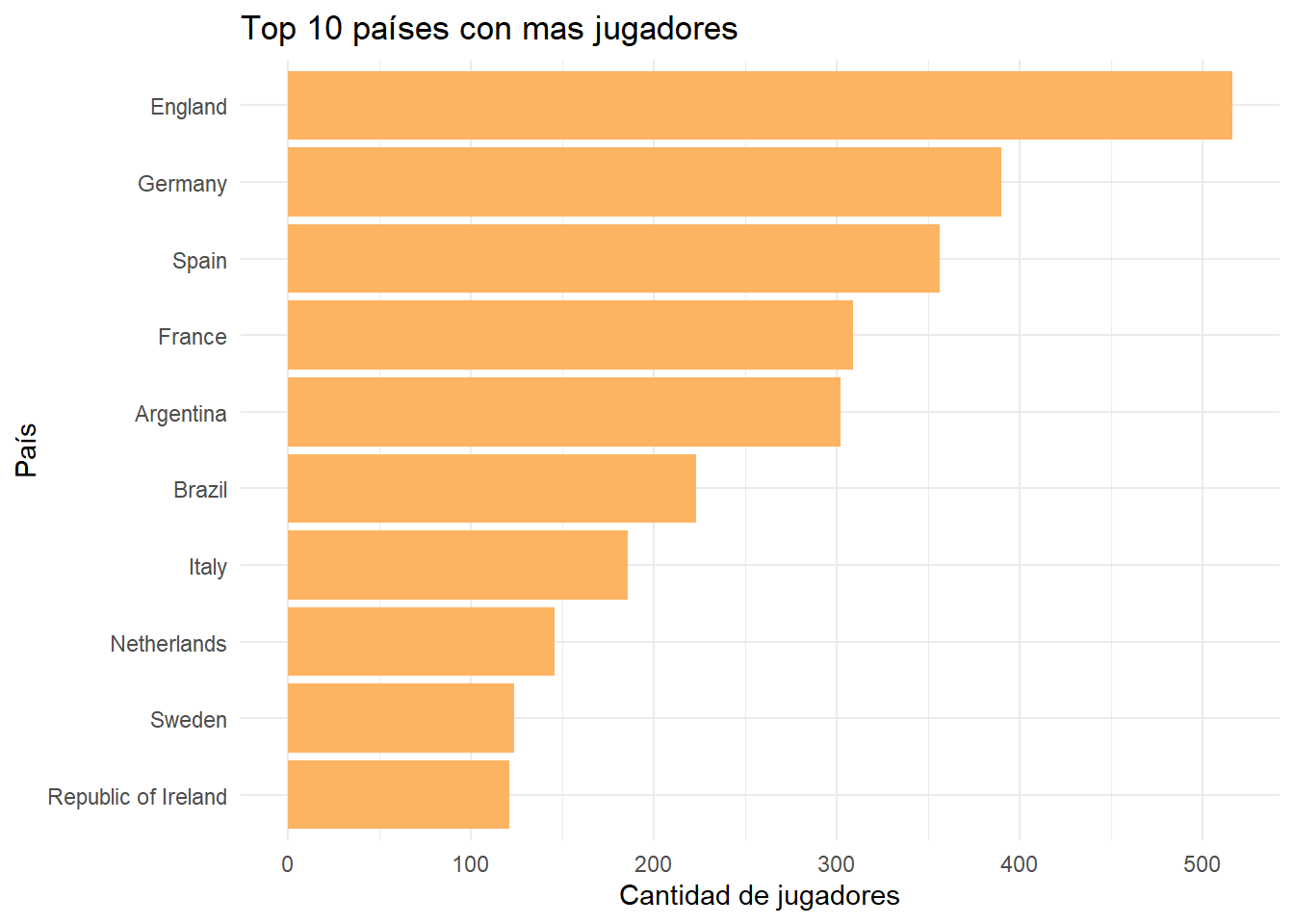
$ country <chr> "Colombia", "Brazil", "Germany", "Austria", "Uruguay", …
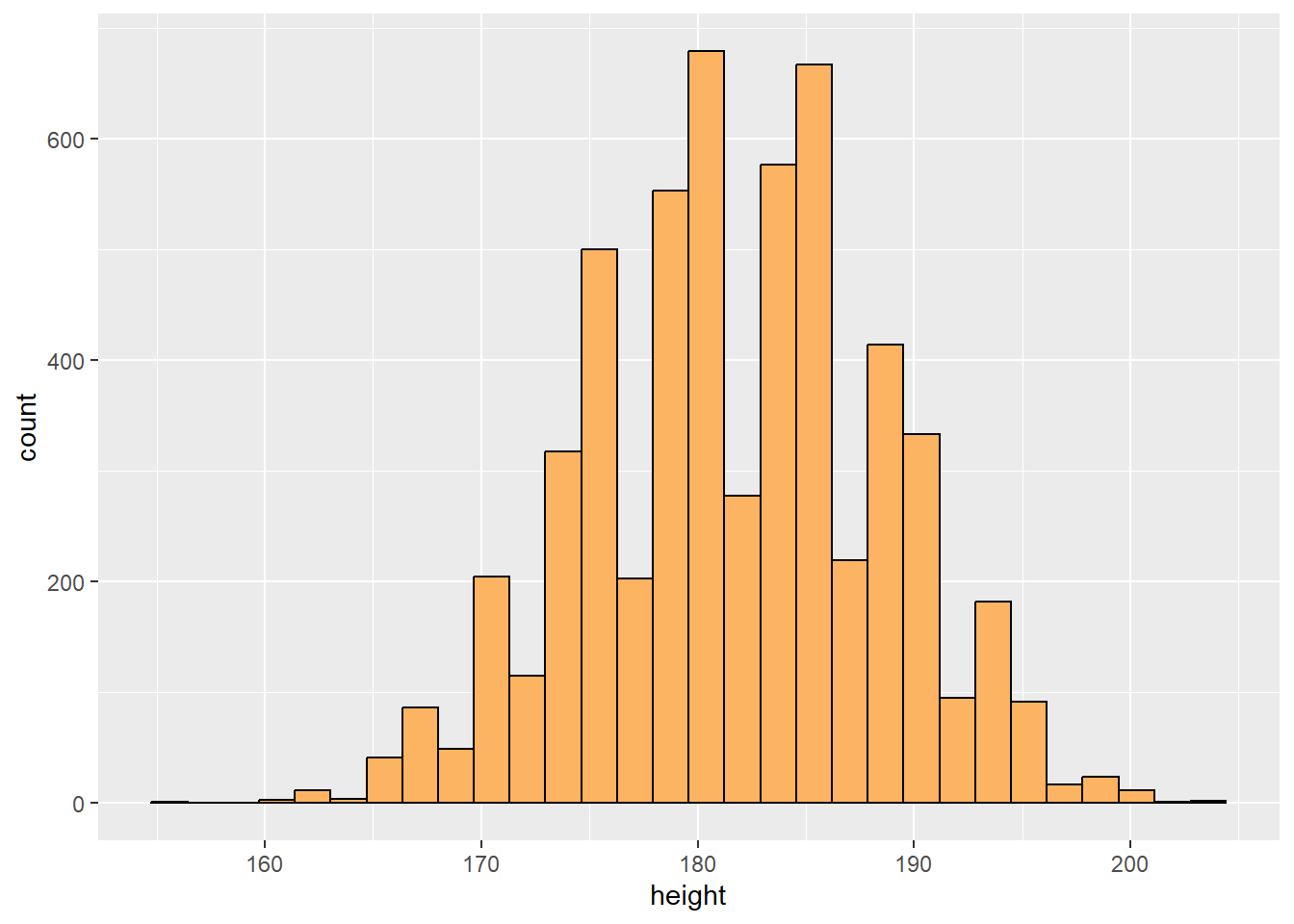
$ height <int> 192, 181, 193, 187, 191, 183, 194, 185, 189, 173, 186, …
$ weight <int> 84, 80, 84, 86, 80, 83, 88, 75, 80, 67, 78, 65, 88, 67,…
$ age <int> 22, 31, 29, 33, 23, 31, 25, 20, 30, 22, 23, 31, 21, 29,…
$ club <chr> "Atl. Nacional ", "Corinthians ", "Holstein Kiel ", "SK…
$ ball_control <int> 55, 69, 25, 46, 14, 20, 52, 41, 68, 65, 62, 61, 45, 54,…
$ dribbling <int> 43, 70, 12, 48, 8, 16, 43, 33, 67, 67, 59, 59, 28, 51, …
$ marking <chr> "", "", "", "", "", "", "", "", "", "", "", "", "", "",…
$ slide_tackle <int> 68, 56, 13, 66, 14, 13, 71, 65, 16, 30, 30, 58, 54, 50,…
$ stand_tackle <int> 73, 58, 16, 69, 16, 17, 72, 70, 22, 33, 24, 59, 58, 51,…
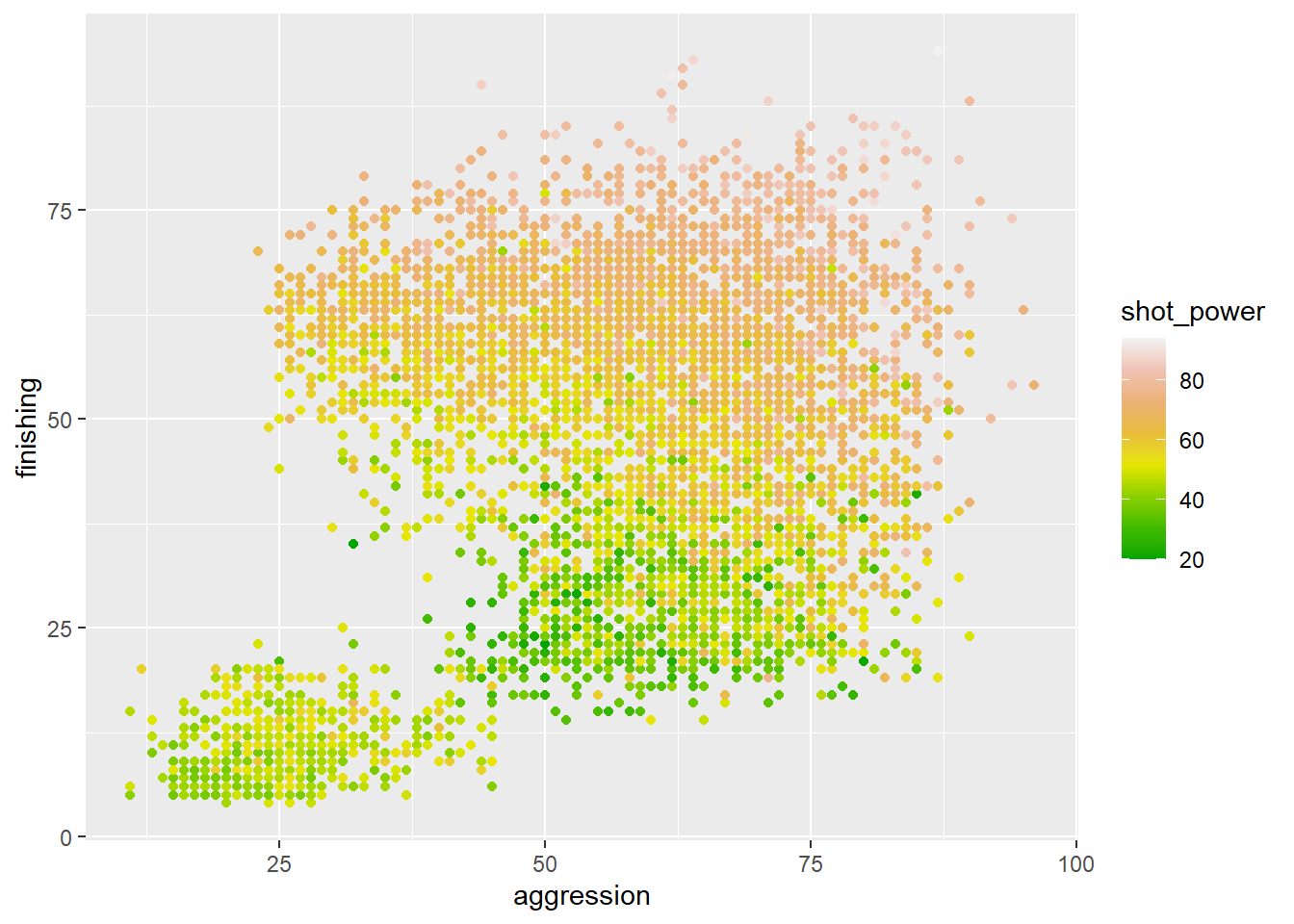
$ aggression <int> 72, 62, 27, 71, 28, 27, 63, 46, 61, 40, 51, 60, 50, 86,…
$ reactions <int> 68, 70, 65, 64, 50, 70, 61, 54, 64, 47, 58, 58, 50, 55,…
$ att_position <int> 30, 69, 17, 48, 10, 10, 37, 27, 72, 65, 62, 60, 25, 56,…
$ interceptions <int> 65, 70, 20, 66, 12, 21, 68, 56, 22, 29, 31, 60, 54, 51,…
$ vision <int> 30, 64, 49, 29, 38, 55, 34, 25, 50, 58, 57, 63, 48, 52,…
$ composure <int> 50, 54, 48, 70, 34, 44, 56, 46, 64, 59, 53, 49, 48, 45,…
$ crossing <int> 33, 60, 14, 44, 11, 10, 43, 26, 33, 60, 58, 51, 35, 51,…
$ short_pass <int> 64, 63, 35, 58, 23, 25, 60, 49, 57, 63, 64, 65, 54, 50,…
$ long_pass <int> 49, 63, 18, 53, 20, 23, 55, 45, 42, 61, 51, 63, 50, 42,…
$ acceleration <int> 41, 64, 46, 35, 38, 55, 55, 63, 53, 81, 71, 74, 61, 73,…
$ stamina <int> 55, 87, 38, 73, 28, 44, 75, 64, 54, 55, 63, 67, 46, 70,…
$ strength <int> 86, 81, 68, 82, 64, 75, 84, 78, 86, 63, 71, 49, 78, 64,…
$ balance <int> 40, 42, 41, 56, 24, 65, 33, 63, 58, 80, 54, 90, 52, 80,…
$ sprint_speed <int> 52, 67, 48, 63, 31, 54, 68, 55, 69, 69, 74, 66, 64, 78,…
$ agility <int> 43, 65, 36, 57, 34, 62, 34, 45, 60, 68, 67, 85, 51, 77,…
$ jumping <int> 51, 65, 60, 80, 27, 72, 74, 71, 73, 60, 74, 71, 60, 58,…
$ heading <int> 64, 54, 17, 67, 13, 21, 74, 55, 76, 47, 60, 48, 52, 51,…
$ shot_power <int> 54, 60, 51, 32, 48, 48, 41, 39, 74, 73, 62, 56, 50, 51,…
$ finishing <int> 30, 64, 14, 24, 4, 14, 33, 21, 71, 53, 60, 48, 25, 33, …
$ long_shots <int> 31, 68, 20, 33, 6, 16, 18, 24, 58, 55, 59, 57, 23, 45, …
$ curve <int> 32, 65, 20, 25, 9, 15, 29, 26, 53, 53, 49, 45, 37, 50, …
$ fk_acc <int> 34, 62, 15, 13, 10, 13, 22, 26, 39, 31, 35, 50, 30, 40,…
$ penalties <int> 41, 48, 26, 22, 16, 13, 34, 39, 72, 58, 57, 49, 41, 50,…
$ volleys <int> 33, 46, 16, 19, 5, 10, 34, 25, 63, 60, 52, 39, 35, 46, …
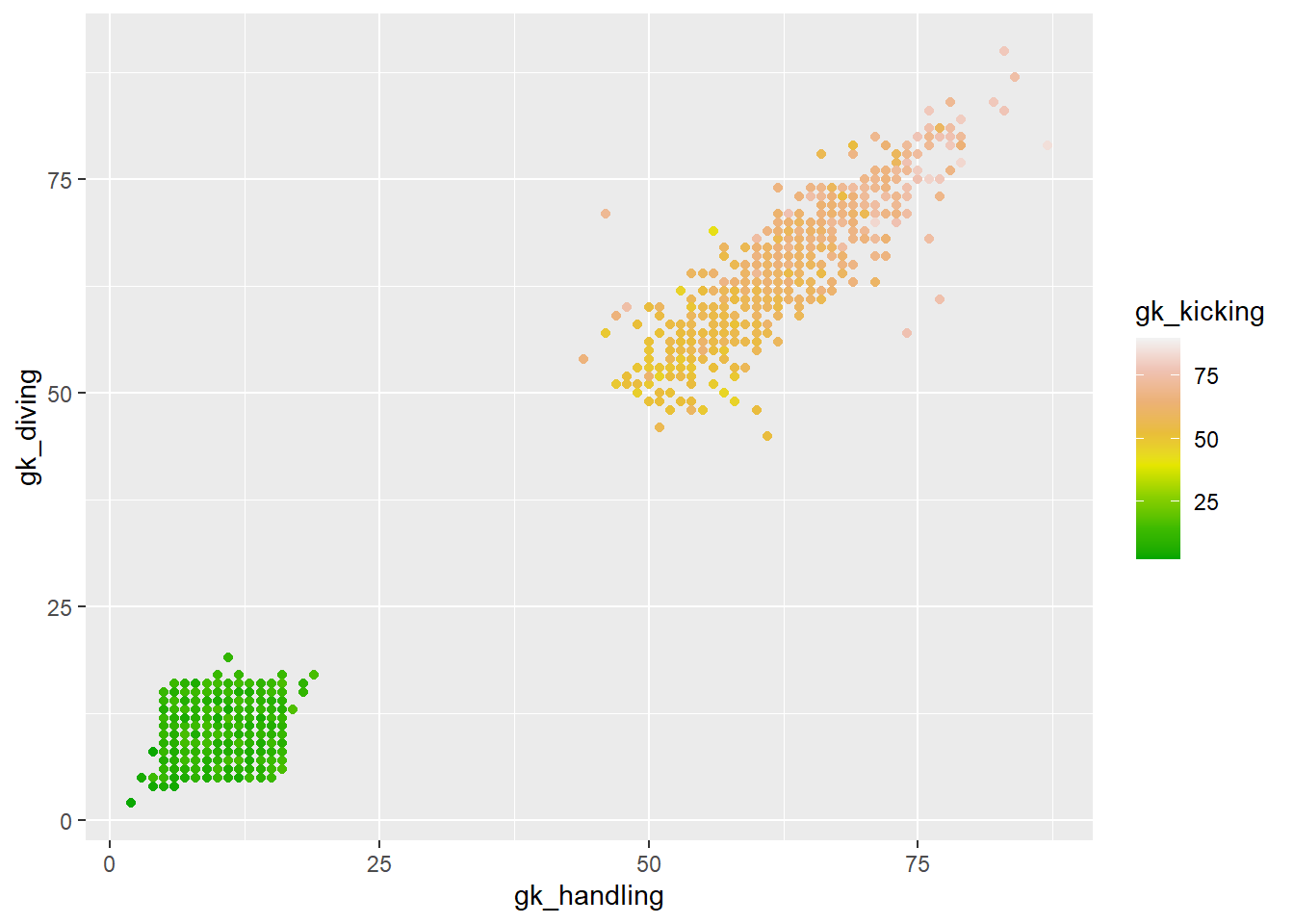
$ gk_positioning <int> 10, 12, 64, 10, 61, 72, 10, 7, 11, 8, 8, 6, 9, 14, 12, …
$ gk_diving <int> 11, 15, 74, 10, 59, 78, 5, 6, 7, 12, 10, 14, 10, 9, 8, …
$ gk_handling <int> 6, 14, 65, 8, 62, 73, 14, 12, 10, 8, 6, 10, 13, 8, 9, 1…
$ gk_kicking <int> 7, 8, 68, 14, 64, 64, 12, 13, 15, 5, 10, 10, 7, 15, 8, …
$ gk_reflexes <int> 9, 14, 74, 9, 64, 74, 5, 11, 12, 15, 10, 11, 13, 11, 12…
$ value <chr> "$1.400.000", "$975.00 ", "$1.100.000", "$650.00 ", "$3…